Huffman Codes - Greedy Algorithms
Invented by a matematician David Huffman.
Huffman Coding is a compression technique that is used to compress text files. We know that all what computer sees is a long stream of 1’s and 0s. Hence, when we type text we get bunch of 0’s and 1’s. All these letters according to ASCII table have some value and each value is represented as 8 bits. That requires quiet a bit of memory. Hence, Huffman invented the first method for compressing this information. Today there are many compression techniques, but Huffman’s was the first one. Today, we compress huge files to send them over email, etc.
If we have a string BCCABBDDAECCBBAEDDCC, we can see that it contains 20 characters. Each character consists of 8 bits => 20 x 8 = 160 bits total for this message.
Fixed sized codes
We can see that we have 5 different values. We do not need all 8 bits to represent these 5 values. We can represent them with 3 bits.
| Character | count | frequency | code |
|---|---|---|---|
A | 3 | 3/20 | 000 |
B | 5 | 5/20 | 001 |
C | 6 | 6/20 | 010 |
D | 4 | 4/20 | 011 |
E | 2 | 2/20 | 100 |
Each character from the string is represented with 3 bits. That means that total memory of the string is 20 x 3 = 60 bits, which is much better. Our string starts with BCC, so according to our table, it will be encoded as 001-010-010…
When we recieve this message, how is our computer going to know how to read this string now? Well, when we compress this text file, we compress the table together with it. That way, the reader will be able to decode the string. This table also requires some memory. The table contains 5 alphabets => 5 x 8bits = 40 bits. For each new code for letter we have 3 bits => 5 x 3 bits = 15bits. So, the size of our table is 40 + 15 = 55 bits.
message + table = 60 + 55 = 115 bits
This is much less than our original message. This was done using fixed-size codes, but we can do even better with variable-sized codes.
Variable Sized codes (Huffman Coding)
There are two major parts in Huffman Coding:
- Build a Huffman Tree from input characters.
- Traverse the Huffman Tree and assign codes to characters.
Steps to build Huffman Tree
Input is an array of unique characters along with their frequency of occurrences and output is Huffman Tree.
- Create a leaf node for each unique character and build a min heap of all leaf nodes (Min Heap is used as a priority queue. The value of frequency field is used to compare two nodes in min heap. Initially, the least frequent character is at root)
- Extract two nodes with the minimum frequency from the min heap.
- Create a new internal node with a frequency equal to the sum of the two nodes frequencies. Make the first extracted node as its left child and the other extracted node as its right child. Add this node to the min heap.
- Repeat steps#2 and #3 until the heap contains only one node. The remaining node is the root node and the tree is complete.
Let us understand the algorithm with an example:
Step 1: Build a min heap that contains 6 nodes where each node represents root of a tree with single node.
Step 2: Extract two minimum frequency nodes from min heap. Add a new internal node with frequency 2 + 3 = 5.
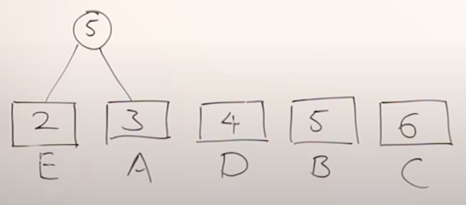
Figure 1 - Building min-heap
Step 3: Extract two minimum frequency nodes from heap. Add a new internal node with frequency 5 + 4 = 9.
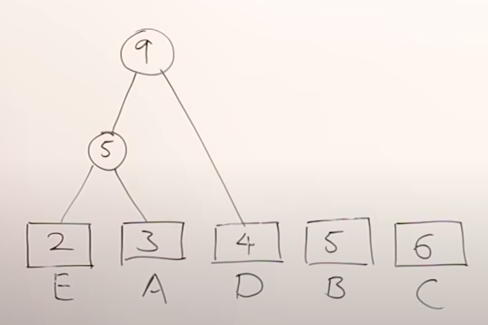
Figure 2 - Building min-heap
Step 4: Repeat the same process until we finish the tree.
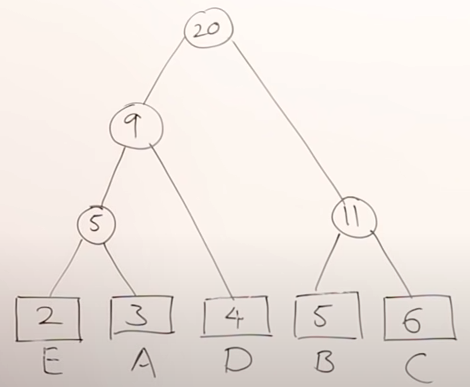
Figure - Finished min-heap
Steps to print codes from Huffman Tree:
Traverse the tree formed starting from the root. Maintain a temporary array. While moving to the left child, write 0 to the array. While moving to the right child, write 1 to the array. Print the array when a leaf node is encountered.
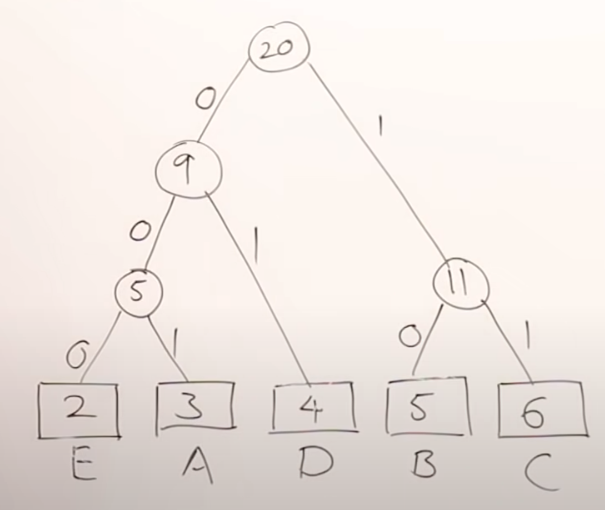
Figure - 0/1 min-heap
From this min-heap we start from the root and follow the path to our characters. For instance, for the character ‘A’ the path contains 0-0-1, so that is the code for it. Our final table would look as follows:
| Character | count | code | message total bits (count * bits) |
|---|---|---|---|
A | 3 | 001 | 3 * 3 = 9 |
B | 5 | 10 | 5 * 2 = 10 |
C | 6 | 11 | 6 * 2 = 12 |
D | 4 | 01 | 4 * 2 = 8 |
E | 2 | 000 | 2 * 3 = 6 |
Total = 44 bits |
Those are our new codes and we can notices that not all of them are 3 bit codes. Some of them are 2 bit codes. The size of the whole message is now 44 bits, the size of the table is => 5 characters x 8 bits = 40 bits + 12bits for codes = 52 bits total. The total amount of memory for the compressed message with the table is 44 + 52 bits = 96 bits! This is even better than fixed sized codes!
Variation of this problem is to decode the given sequence of bits.
The Squid