Data Structures for Disjoint Sets
One of many applications of disjoint data structures is determining the connected components of an undirected graph.
Disjoint sets are the sets that have no element in common. If we were to perform an interception between two disjoint sets, we would get an empty set.
Each element of a set is represented as an object and we wish to support the following functions of the objects:
- Make-Set(x) - This function creates a new set whose only member is x. Since this is the matter of disjoint sets, the element x must not exist in any other set.
- Union(x,y) - This function unites the dynamic sets that contain x and y, which results in a new set that is union of the two united sets. Since the sets that contained elements x and y originally are united into a single set and since we cannot have sets with the same elements, we must destroy the original sets where x and y came from and keep the freshly produced dataset.
- Find-Set(x) - This function returns a pointer to the set that contains the element x.
The following CONNECTED-COMPONENTS procedure uses disjoint-set operations to compute the connected components of a graph.
CONNECTED-COMPONENTS(G):
for each vertex v in G.V:
MAKE_SET(v)
for each edge(u,v) in G.E:
if FIND_SET(u) != FIND_SET(v)
UNION(u,v)Problem 1:
Suppose that CONNECTED-COMPONENTS is run on the undirected graph G = (V, E), where V = {a, b, c, d, e, f, g, h, i, j, k} and the edges of E are processed in the order (d,i), (f,k), (g,i), (b,g), (a,h), (i,j), (d,k), (b,j), (d,f), (g,j), (a,e).
Solution:
- First, we create set with d,i edge –> make_set(d,i) = S1{d,i}
- Repeat, S2 = {f,k}
- Since (g,i) contains element i that is already an element of another existing set, we will perform union of these 2 sets and remove the original set of i.
Existing sets:
- S2 = {f,k}
- S3 = {d,i,g}
4.(b,g)
Existing sets:
- S2 = {f,k}
- S4 = {d,i,g,b}
6.(a,h)
Existing sets:
- S2 = {f,k}
- S4 = {d,i,g,b}
- S5 = {a,h}
7.(i,j)
Existing sets:
- S2 = {f,k}
- S5 = {a,h}
- S6 = {d,i,g,b,j}
8.(d,k)
Existing sets:
- S5 = {a,h}
- S7 = {d,i,g,b,j,f,k}
9.(b,j) since both elements are in the same set, this means that there is a cycle in the graph.
Existing sets:
- S5 = {a,h}
- S7 = {d,i,g,b,j,f,k}
10.(d,f) since both elements are in the same set, this means that there is a cycle in the graph.
Existing sets:
- S5 = {a,h}
- S7 = {d,i,g,b,j,f,k}
11.(g,j) since both elements are in the same set, this means that there is a cycle in the graph.
Existing sets:
- S5 = {a,h}
- S7 = {d,i,g,b,j,f,k}
12.(a,e)
Existing sets:
- S8 = {d,i,g,b,j,f,k,a,h,e}
Linked Lists
Each set in this example can be represented using a linked list. Each member of the list contains the set member, the pointer to the next object in the list , and the pointer to the previous member in the list. The order of the objects in the list does not matter.
In this case, Make_set(x) and Find_Set(x) require O(1) time. For Make_Set we just create a new linked list with the the only element x. For Find_Set(x) we just return the member variable in the object that we are pointing to.
However, the Union(x,y) function would take much longer O( $n^2$ ).
A weighted Union Heuristic
Union(x,y) in average takes O(n) time because we may be appending a longer list to the shorter one. What if we could always append only the shorter list to the longer one? We can do that by applying weigted-union heuristic where each list also includes the length of the list. Then we will always be able to append the shorter list to the longer one.
Problem 2

Problem 2
Show the status of the data structures using linked lists:

Problem 3
Show the result of hte following code:
for i = 1 to 16:
MAKE-SET(x_i)
for i = 1 to 15 by 2:
UNION(x_i,x_i+1)
for i = 1 to 13 by 4:
UNION(x_i,x_i+2)
UNION(x1,x5)
UNION(x11,x13)
UNION(x1,x10)
FIND-SET(x2)
FIND-SET(x9)
Result:

Time Complexity of Linked-list disjoint sets:
Since we performed m operations on n objects, we can assume that this requires $O(n^2)$ time. We execute Make_Set n times followed by n-1 union operations. Hence the total number of objects updated my the Union function is $\sum_{i=1}^{n-1} i $= O($n^2$). \sum_{i=1}^{10} t_i Here is another example where the i, or the “what to sum,” is different:
\sum_{i=1}^{100}(2i+1)
Disjoint-set Forests
In this case we use trees to represent sets. When making a set, we only have the root and its value. Every other object that is being added to the set points to its parent. Using the trees straight forward will not improve the execution time. However, there are two heuristics: union by rank and path compression that can reduce the execution time.
In this approach, Make_Set(x) creates a new tree with the root x. Find_Set(x) will iterate from the given node until reach the root because the root node represent the whole set. Union(x,y) causes the root of one tree to point to the root of the other tree.
Heuristics for runtime improvement
Union by rank - in this approach for each node we assign a rank to each node. Rank represents the upper bound on the height of the tree. Finally, we make the root with smaller rank point to the root with the larger rank during the Union(x,y) operation.
Path Compression - this approach does not change any ranks, but rather changes to what node children point to. If there is a child of another child, the last child will point to the root. This process repeates until all nodes point to the root.
Let us see how would pseudo-code for the functions look like:
MAKE_SET(x)
x.p = x
x.rank = 0
UNION(x,y)
LINK(FIND_SET(x),FIND_SET(y))
LINK(x,y)
if x.rank > y.rank
y.p = x
else x.p = y
if x.rank == y.rank
y.rank = y.rank + 1
FIND_SET(x)
if x != x.p
x.p = FIND-SET(x.p)
return x.pProblem 4
Show the status of the data structures using disjoint forests with union by size and path compression:
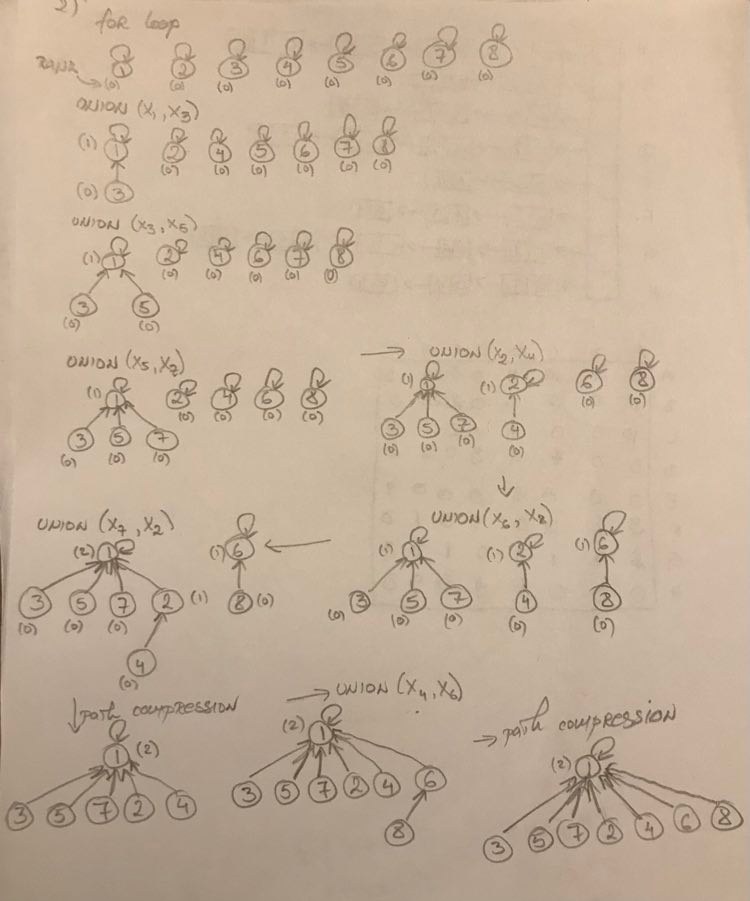
Problem 5
Write a non recursive version of FIND-SET(x).
ANSWER:
FIND-SET(x):
# create a linked_list
A.root = x
while x not root:
x = x.parent
A.add(x)
#snice x is the root add it to the list and set it as root
A.add(x)
A.x = root
return A.root
Time Complexity of disjoint-set forests:
If we perform m operations and if there are n elements, the time complexity will be O(m α (n)), where α (n) is a very slow growing function that is <= 4. This time complexity then turns into O(4m), which is O(m).
The Squid